
Note: This page was posted for April Fool’s Day 2012. :D
You have probably already used Transifex successfully to translate apps from English to other languages, like Spanish, French and Chinese. Our technology allows developers to take content from one language and translate it to another one, by splitting the work in small tasks, which can be independently translated, thus, crowdsourced. It is working very well for spoken languages, but there are also other areas where it could be useful.
Every now and then, when we explain what Transifex does, we get the following question: “When you say ‘translating’, do you mean between spoken languages or programming languages, like C and Python?”
The answer has been the former, but the latter always sounded uber-cool. So, because we like making people happy, we decided to add support for translation between programming languages. Transifex users will now be able to translate not only from English to Spanish, but also from Python to C, Perl or PHP.
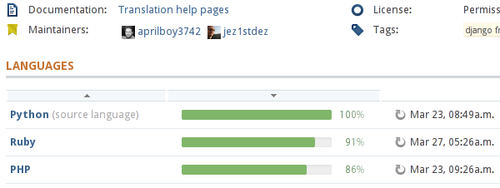
Here’s an example input and output of the initial run of the machine translation module from Python to Ruby:
| Python | Ruby |
def fib(n): |
def fib(n) |
Technology
Using technologies like Natural Language Processing, which is already available in Transifex, and a combination of compiler technology, finite-state automata and genetic algoritmhs, Transifex offers a rough translation between the two languages. Then, the user can review and correct the translation using our web-based editor.
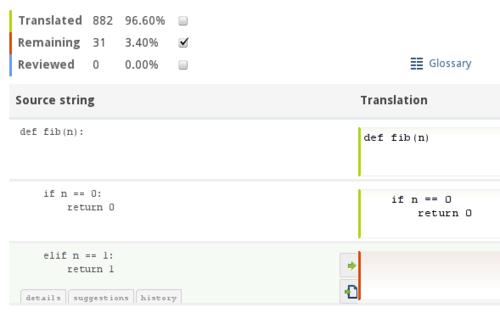
Here is a blueprint of the under-the-hood technologies used:
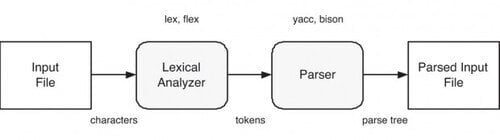
- Lexical Analysis: The source language is defined using certain rules, which are fed to the lexer. These are mostly defined using BNF. So, the lexer can identify the tokens, delimiters and keywords. In order to support many languages as input, we have a different set of rules for each language. Once the lexer tokenizes the content, it passes the result to the parser, which combines the tokens together.
- Syntax Analyxis: The output from the lexer is parsed in order to build the Abstract Syntax Tree of the source code, which is a simple representation of the original source code. The parsed output is saved to the database.
When the output is requested in a particular programming language, we use the stored AST of the program and apply the reverse procedure to generate the source code in that language which would correspond to that AST. Custom functions have been developed for this reverse procedure that try to generate as simple and readable code as possible. However, since efficiency is often important, too, the generated code can be hand-edited with lotte, the web-based editor.
Language pairs supported
We are launching our first version with the following language pairs:
- Python ↔ Ruby
- Python ↔ Javascript
- Ruby ↔ Javascript
- Python → Perl
- Python → PHP
- PHP → C
We are rolling this in Beta for a selected group of users. If you would like to use it, drop us a note in the comments section of this post.
Note: This page was posted for April Fool’s Day 2012. However, if you've been tasked to translate you app, look no further. We've created a series of detailed tutorials for some of the most common programming languages: