


Localization is never easy, but there are some situations that will turn a difficult process into a complete nightmare. After resurfacing some repressed memories, we found five surprisingly common issues that drive developers and localizers up the wall. In this post, we'll show you how to approach and resolve these issues before they make you loopy.
1. The Software Localization Paradox
There's a counterintuitive pattern in software localization: the people who are best suited to localizing also tend to be the least interested in using localized software. The problem stems from the widespread use of English in computing combined with a lack of good translations. If a user doesn't know English, they have to memorize the English interface, work with a poorly translated interface, or not use the software at all. On the other hand, if the user does know English, he or she will likely prefer the English interface over the localized version.
The result is an endless cycle of dependency. The software needs users to translate from English to their native language, but native speakers who know English tend to prefer the English software. The lack of users willing to localize software in their native language results in fewer users using the localized software, which results in fewer users willing to localize, and so on.
What's the Solution?
Some organizations have the luxury of hiring dedicated professional translators who have a fluent understanding of the current language and target language. If there's a large enough demand for the software in a particular region, a company can easily recover the money spent on a localization team in sales.
On the other hand, some organizations source their translations directly from their users. With Transifex, this has become a much more viable alternative. Crowdsourcing translations is a way for companies to expand their market reach while simultaneously connecting with users. Some of the web's most popular projects including Discourse and Eventbrite rely on crowdsourced translations.
2. The Turkish Problem
There's one country that always seems to come up when discussing localization: Turkey. Turkish localization is so notorious that it even has its own battery of tests known as the Turkey Test. The problem we're looking at specifically is how text is converted between English and Turkish. Take a look at the following Java code:
String inputLower = "input";
String inputUpper = "INPUT";String inputLowerToUpper = inputLower.toUpperCase();
if (inputUpper.equals(inputLowerToUpper)) {
System.out.println(inputLowerToUpper + " is equal to " + inputUpper);
}
else {
System.out.println(inputLowerToUpper + " is not equal to " + inputUpper);
}
Seems simple enough, right? We convert a string from lower-case to upper-case and compare it against its upper-case equivalent. If they're the same, then we say they're equal. If not, then they're not equal.
INPUT is equal to INPUT
At least, it is as long as you're not Turkish. It turns out the Turkish alphabet has two extra representations for the letter i: the dotless lowercase i and dotted uppercase I.
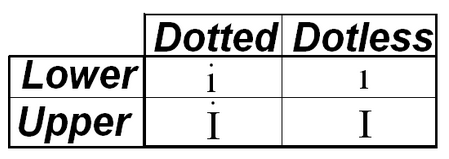
Credit: i18n Guy
When the program goes to convert inputLower to its upper-case Turkish equivalent, it uses the dotted İ instead of the dotless I, and the comparison fails:
Locale turkishLocale = new Locale("tr", "TR");
Locale.setDefault(turkishLocale);
String inputLower = "input";
...
İNPUT is not equal to INPUT
What's the Solution?
We need a way to compare the two strings in a non-linguistic way. Using the Java program from above, we perform what's known as an invariant culture comparison by converting the lower-case string to its upper-case equivalent using the en_US locale. That way, we're comparing two strings formatted in the same locale:
String inputLowerToUpper = inputLower.toUpperCase(Locale.US);
You can perform a similar test using an ordinal comparison, which compares each character in the string based on its underlying bytes. Ordinal string comparisons are generally preferable to invariant culture comparisons, although both will work in most situations.
3. Time is of the Essence
If you've ever tried to implement timezones in software, you know how difficult the process can be. The world has a total of 40 time zones. Some time zones are offset by a fraction of an hour rather than a full hour. Some areas of the world, such as the Gaza Strip and West Bank, even have multiple time zones in the same geographic region.
Not only that, but timezones change: In 2007, Venezuela set its clocks back by half an hour, while in 2011 Samoa lost an entire day by jumping to the other side of the International Date Line. North Korea created its own new time zone on August 15th, over 100 years after both North and South Korea set their clocks nine hours ahead of GMT. And if you think that's hard to keep track of, just wait until you have to account for Daylight Savings Time!
Tom Scott provides a much more vivid explanation of why time zones are such a problem for developers. In short, time zones are complicated, dynamic, and hard to track without dedicated resources.
What's the Solution?
The solution is to use an existing library that already tackles the problem of time zones. Google recently released CCTZ, an open-source library for C++. CCTZ represents time in two ways: absolute time, which represents a specific and universal point in time similar to a timestamp; and civil time, which represents absolute time in a specific region. Civil time accounts for time zones, but absolute time is the same for everyone. You can convert from civil time to absolute time and vice versa, as long as you know the time zone that the civil time is based on.
Similar libraries also exist for other languages. Java contains the built-in java.util.TimeZone and java.util.Calendar classes, Python has pytz, and PHP has the built-in DateTime class. If you need to compare dates from two different time zones, a good method is to base the comparison on a single standard such as UTC. Then, use the library to format and display the final result.
Before implementing any kind of time tracking, refer to your language's documentation for details on handling time zones. Most importantly, don't try to implement time zone tracking yourself, because, as Tom Scott put it, "that way lies madness."
4. User Input or: How I Learned to Stop Worrying and Love Unicode
Much of the localization process focuses on output. However, if your application supports direct user input, you have to look at the other side of the coin. How well will does application handle input from users in Russia, China, Egypt, or India? Can it read characters, dates, and numbers from different locales, or from right-to-left languages? If it needs to send that data to an external service, such as a database, how well does the service handle the locale?
What's the Solution?
Unicode is the current standard for language support in software. The most common character encoding is UTF-8, which is used by over 85% of websites as of this post. If your application supports UTF-8, then it already has the ability to interpret characters from almost any written language. For languages that don't support natively UTF, look into functions or modules that allow you to change the default character set.
Other forms of input will need to be handled on a case-by-case basis. Numbers (including phone numbers), addresses, currencies, measurements, dates, and times all need to be adapted to the user's locale. For many of these (dates, times, and numbers), you can store user input in a standardized format. Otherwise, you may need to instruct your users on how to format their input or provide an alternative UI for unique cases.
5. Why "Your" And "Your" Aren't Always the Same
Imagine you're developing an online storefront. You've just finished internationalizing and you're ready to start adding languages. As part of your interface, you have a line of text that shows the number of items in the user's shopping cart. For example, if a user has 5 items in the cart, the store shows "You have 5 items in your shopping cart." You might have broken the rules a bit by using string concatenation, but you only did it to make your store more user-friendly. No harm no foul, right?
All of a sudden you get a call from your Spanish localizers. They want to know if they should use "you" in the formal usted or in the informal tú, and in either case, whether "you" refers to one user or multiple users. You tell them it's for a single user, and since you don't want to tread on any toes, you tell them to use the formal usted. Shortly after, you get a call from your Arabic localizers, who need to know if "you" refers to a man, a woman, two men or two women, or multiple men or multiple women.
Say you manage to account for all of these cases in all of your supported languages. You suddenly get a call from your Russian localizers, who are having trouble working around the limited support for plural numbers. They need the application to support three plural forms: one for numbers ending in 1, one for numbers ending in 2 through 4, and one for numbers ending in 5 through 9 (plus 0). Shortly after, you get another call from your Arabic localizers, and all heck breaks loose.
What's the Solution?
The source of most grammatical conflicts is simple string concatenation. The same sentence that seemed so simple in English has dozens of conjugations, gender agreements, and plural forms in other languages. When the contents of a string are dependent on the contents of a variable, there's no way of knowing how to format the string without creating dozens of use cases for each language. The key is to remove this dependency by removing the variable from the string entirely.
Using our shopping cart example, you can reserve the conversational translation for English while using a simplified version for other languages. For instance, an English user would see "You have 5 items in your shopping cart," whereas a Spanish user would see the Spanish translation of "Number of items in the shopping cart: 5." It's not as user-friendly as the English translation, but it's much easier on your localization team.
As an alternative, localization frameworks can provide for complex grammatical rules. The Unicode Common Locale Data Repository (CLDR) supports locale-specific formatting, parsing, and name translation, as well as countless other resources.
Have you come across any localization issues that have made your head spin? Let us know in the comments.