TX Labs: A Space for Accelerated AI Innovation
3 min read
 “Designed by pressfoto / Freepik”
“Designed by pressfoto / Freepik”Written by Yiota Ziaggou & Christos Andrikos
At Transifex, we love moving fast and pushing things forward! That’s why we created Transifex Native: a simple and lean, yet powerful open-source Software Development Kit (SDK) enabling what we call “the next-generation localization”. Transifex Native aspires to become a core component of every single project requiring localization which helps to move beyond file-based localization operations and enhance the experience of the end-user. It also provides quite an intuitive (yet ICU-standardized) syntax that is designed to make coding localization pleasant. And you know what, it worked!
You may be thinking,
“Nice work, guys. This may work for newly introduced projects, but I am not even close to considering updating the localization parts of my project! I don’t even know what is going on with them.”
And you are probably right! But at Transifex, we never leave our customers without novelties plus we love challenges. So we thought that “tasting our own dog food” would be a good idea! And the migration journey started for a couple of engineers…
First thing first! We started focusing on the unknowns of the migration. Affording a code migration script we were confident enough that most of the remaining work was related to dealing with any automation issues or with the manual QA testing. On top of this, we were aware of potential coordination issues that would be raised. The entire company was still working on evolving multiple aspects of our product that could trigger conflicts and delays. We had to answer questions related to both the operational and development side:
For starters, we wanted a rather small team to work on this (~4 engineers), given that all the tools needed for migrating our content (from our file resource to a fileless one) were already there. We also needed the help of our PO (Product Owner) to coordinate with other departments in order to inform our translators of the forthcoming change. The idea was to release the content gradually in order to better track what is being released each time and to monitor the process.
First of all, we needed to decide the best way to proceed given our application’s structure. There are various ways we could have moved forward based on that. Given that our Application is using Python/Django/Javascript, and our localization strings are included in two of those, (Python/Django) we thought of two ways that this migration process could work for us.
We decided to proceed incrementally and release batches of files that contain the localized content.
Getting closer to the release of the first batch we had to also test the pushed strings and the modified files to make sure the result would be as expected. That would mean no new strings present (which was easy to identify from the push report), no other issues while pushing, and no broken strings present via the Editor.
So a successful report after running the push command:
./manage.py transifex pushwould look like this:
Parsing all files to detect translatable content...
Processed 3841 file(s) and found 476 translatable strings in 2 of them
Pushing 357 source strings to Transifex...
Successfully pushed strings to Transifex.
Status: 200
Created strings: 0
Updated strings: 357
Skipped strings: 0
Deleted strings: 0
Failed strings: 0
Errors: 0** While running the migration, we chose to use this command:
./manage.py transifex migrate -p FOLDER_PATH --save replace --mark string-low–save replace, as we didn’t want the script to create new files
–mark string-low, as it would prompt us for the low confidence strings. Therefore, it would be much easier to search through the migrated files and make adjustments in the new syntax wherever needed.
We needed to take into consideration:
{% t num=entries|length %}
{num, plural, one {Project} other {Projects}
}{% endt %}This was wrong as there should not be any spacing before/after the plural rule.
While this:
{% t num=entries|length %}{num, plural, one {Project} other {Projects}}{% endt %}was right.
Also, if we wanted a string to be the same before and after the migration of the file, we needed to pay attention to the spacing in general.
This:
{% blocktrans with organization.name as orgname %}
I understand, proceed with {{orgname }} deletion
{% endblocktrans %}Is different from this:
{% blocktrans with organization.name as orgname %}
I understand, proceed with {{orgname }} deletion
{% endblocktrans %}If our {% blocktrans %} template tag had space before the migration, we had to make sure to keep it after the migration, if we wanted the string to have the same key/hash (this would mean that we would not lose the strings data, such as its translation, context, comments, history, tags, etc.).
Now, in Transifex, when we create the .po file, we convert the {{variable}} to %(variable)s
and the latter is set to be recognized by the Transifex Application as a default variable, like this:

We needed to add the same logic for the fileless format so that the new {variable} could be recognized as well by default. Given the above string, we would now have this:

We also use this type of variable $(variable) which is now added as a custom variable for the specific fileless format.
We needed to include a data migration in order to keep all the context we already had for our strings. This, however, could only run once; from then on, the old resource would have to be obsolete and our translators could not make any changes to it.
This data migration had to precede the first push of strings in the fileless resource. Any time we push a batch of strings, the related context will apply to the currently pushed strings since they would feature the same key.
We thought it was a good idea to inform our translators as soon as the data migration had run and after the fileless resource was present. This would mean that the old resource would be obsolete, as mentioned before, so the translators should only work on the new resource.
During the whole process, we had to properly inform our engineering team as well, so they do not implement work in any of the files of the current batch and we could avoid potential conflicts. If such a case occurred, we had to be informed in order to make proper adjustments in the modified file, add the change, and rerun the migration script (or in case it was something small, do it manually)
Considering the size of our codebase, the trickiest part of a migration like this was the final QA testing. To overcome this challenge, we decided to break down the folders into batches, then run the migration script per batch, and finally add any report data into a detailed spreadsheet. In this way we managed to perform multiple batch-oriented QA tests. After every migration of a single batch, we were confident that the end-user experience had not deteriorated.
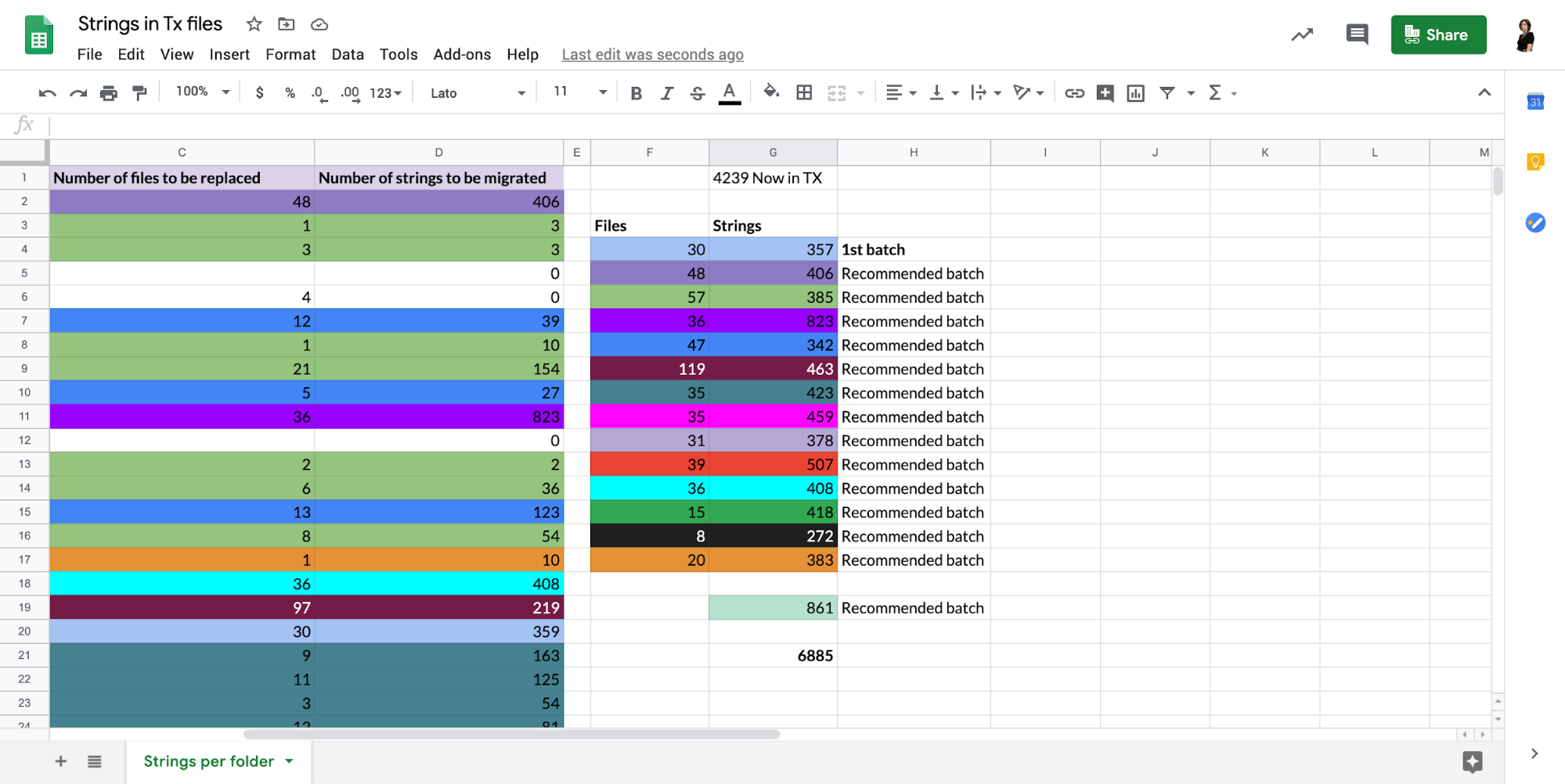
Following this, we could group the folders per number of files that will be migrated, number of strings, and relevance between the files/folder along with the related invocation in the Transifex Application. That way, we created a number of X recommended batches. We had to keep in mind that the file batches could not consist of too many files as it would be difficult to review the changes. We tried to keep each batch size around 30-50 files. It is worth mentioning here that by comparing the total number of strings to be migrated per folder with the total number of strings in our current resource, we calculated a difference of about 2,500 strings over the current resource. That difference occurred through the repeated strings and was reduced each time we pushed a batch in production to the new fileless resource.
Up until now, we had automation in place that would generate our current .po file, using Django ./manage.py makemessages, every time a new deployment process was initiated. We had to intervene there, too, and replace that automation with a new one. Any engineer that worked on any of the Django or Python files that included strings the old way had to convert it to the new ICU syntax.
Given that we have the plan in place and the first batch is released, all we have to do next is to stick to the plan and proceed with the rest of the batches following the same process:
Apparently, the first iteration seemed to be a little overwhelming as many unknowns had to be faced. However, given our solid plan, the batch division, the migration tool with its more than helpful parameters, and the data migration process, it all turned out to be the best approach giving us confidence that everything will fall into place properly.
I hope this helped you gain an insight into our process and boost your confidence to try Transifex Native out on your localization projects. Feel free to reach out to us for more information or questions. Our team is working hard to help our users achieve a new and improved localization experience.