TX Labs: A Space for Accelerated AI Innovation
3 min read

Recently we launched Transifex Native, an end-to-end cloud-based localization stack that brings a new paradigm to the continuous development and localization workflow. One of the decisions we made around Native was to make it open source and to fully enable the wider open-source community to take advantage of our architecture and build on top of it.
One of the main components of Native is the SDK (software development kit). We started by creating a Python SDK that also has support for Django, and we plan to support more programming languages and frameworks. However, there are countless options out there and, even if we only consider the most popular ones, there are still at least a dozen left.
Therefore, we want to allow developers outside of Transifex to contribute by porting Native to new languages and frameworks.
Implementing a new Native SDK poses some interesting engineering challenges, in terms of designing a good architecture and creating highly usable APIs. Every such SDK has several required parts that are necessary for the solution to work and there are certain specifications that need to be followed, such as how to communicate with the Transifex Content Delivery Service (CDS), or the kind of metadata that Native supports. Finally, there are particular challenges that are common to all Native SDKs, such as dealing with ICU Message Format, escaping strings, handling plurals, and generating unique keys.
In order to help developers create new SDKs, we decided to craft a detailed guide with all the material that would make their work as straightforward as possible. This is how the Native Specifications document came to life.
There are a few interesting decisions we made regarding the content and the structure of this guide, and we’d like to share them with you, as we believe they could apply to other similar guides for Open Source software.
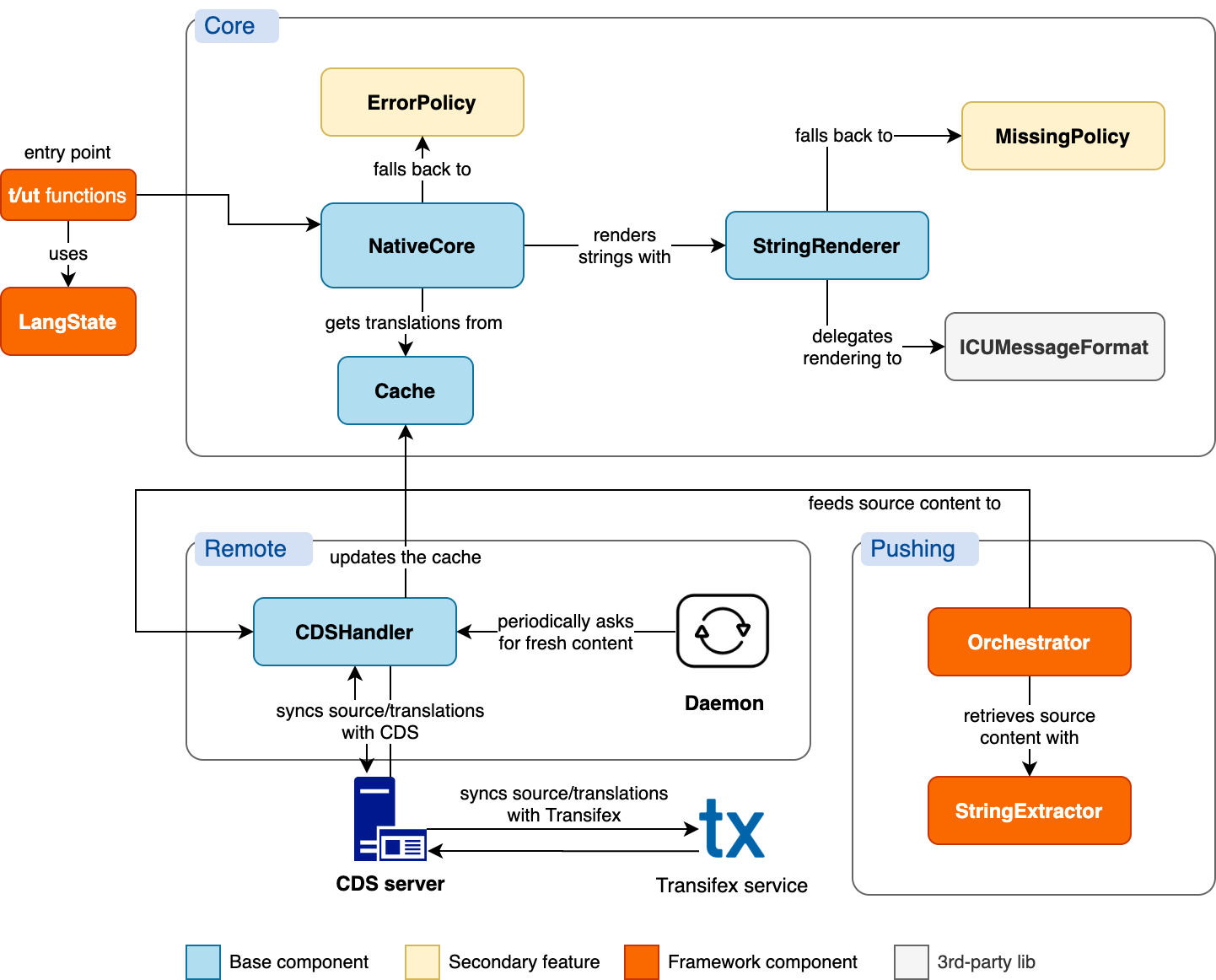
Each Native SDK has several distinct functionalities that it must implement, such as providing a way to mark localizable phrases, detecting phrases in the source code & pushing them to CDS, fetching translations from CDS, rendering translations from ICU strings, and handling empty and erroneous translations.
These are not few in number, and they have inter-dependencies. So, the first thing we did in the guide was to provide a high-level architectural diagram and explain what the responsibility of each component is. This is followed by a set of concepts, like the handling of plurals, that are common in all Native SDKs.
Each developer has their own development style. Some prefer to solve the core of a problem first and then get to the peripheral functionality, while others may choose to start from the point of entry for a new system and work their way through the core, thus giving priority to the public API of the system.
It shouldn’t matter what approach someone picks, but for an SDK with several moving parts, like Native, it can be helpful to know where to start from and what to expect as you build the various components of the system.
For this reason, we came up with a step-by-step guide that can help developers focus on what’s more important at any given time. Since we faced quite a few challenges during the development of the Python/Django SDK, it felt natural to share our findings in a structured way for the community.
The implementation guide makes suggestions on what to work on at each step, highlighting pitfalls, things to pay attention to, things to ignore for the moment, and the respective expected outcome.

This way, developers can have a working software at each milestone, without having to go through the daunting task of reverse-engineering an existing SDK.
pseu·do·code / ˈso͞odōˌkōd / noun
a notation resembling a simplified programming language, used in program design.
Instructions are always useful, but nothing speaks like code to developers. While we had the whole codebase of the Python/Django SDK publicly available, we decided to take the time and rewrite a lot of its parts as pseudocode for the guide.
There were three reasons for this decision:

An important concept of the guide is that it hides anything that is optional at each step. This goes all the way down to pseudocode and function arguments. For example, a very useful feature of Native is the handling of empty translations, but it is not vital for its core functionality.
Therefore, in the first steps of the guide, the initialization functions have no mention of a handler for empty translations, to allow developers to focus on what is really important and reach a working state of the software faster, as Agile principles dictate. In later stages, the provided pseudocode is updated with the related function argument, and developers can implement this feature.
Another feature of the guide is that it provides input and output data in as many cases as possible, so that developers know if what they are building is working as it’s supposed to.

They can use the input and output to create unit tests, without having to come up with proper values themselves. This can be a time-saver, but mostly it’s a boost of confidence that the work they are doing is on the right track.
This goes without saying, but the guide also provides detailed payload examples of the requests the SDK needs to make to CDS, as well as the expected response payloads.
In addition to this, the pseudocode in the related section shows how the JSON data from CDS should be accessed, in order to store the translations in the cache layer of the SDK.
The creation of the specification guide was both a lot of fun and a big challenge in terms of effort. We knew it wouldn’t be easy, but we probably underestimated some of the required work.
One example is pseudocode; writing easily digestible samples, while filtering out the unnecessary details, proved to be very time-consuming and it wasn’t the easiest of tasks. We managed to cover a large part of the actual SDK in pseudocode, but we deliberately left out the most complex algorithmic parts, as we decided that they couldn’t possibly be easier to read than the actual code, and the results wouldn’t justify the effort.
The first version of the document is out! We want to make this as helpful as possible for all developers out there that want to contribute. There might be cases of languages and frameworks that need some kind of a different architecture or have corner cases that are not currently covered in the guide. We want the help of the community, so if you have any suggestions please share!
Photo credit: NESA by Makers on Unsplash