What is Software Localization: All You Need to Know
12 min read
 Security has been, and still is, the single most important topic of discussion, in tech circles, for ages. There definitely isn’t a straightforward way to solve all of your security concerns, and neither can it be considered one of those things that you do once and can then forget about. It should be an “always-in-progress” project, to be visited regularly and treated with attention to every little detail.
Security has been, and still is, the single most important topic of discussion, in tech circles, for ages. There definitely isn’t a straightforward way to solve all of your security concerns, and neither can it be considered one of those things that you do once and can then forget about. It should be an “always-in-progress” project, to be visited regularly and treated with attention to every little detail.
If you have been following our blog, you must know that all of our applications run in a Kubernetes environment. These applications use multiple passwords, tokens & keys (i.e. secrets) to communicate with one another and with external services. Leaking one of these would not mean the end of the world, but the most important ones could cause some damage if mishandled. Up until recently, these secrets were stored in our CI/CD tool of choice, Jenkins.
Jenkins encrypts every secret using AES[1] and stores it in its filesystem. Our deployment pipelines would get the secrets they need, and pass them on to the application being deployed. This was a good enough way of doing things, but we had a few problems with it.
For starters, the grouping of the secrets was not pretty – it was hard to figure out which secret someone wanted to use, and it was easy to create duplicate secrets. This caused a lot of headaches and frustration. In addition, access to them was tied to Jenkins, and its host machine, which translates to “single point of failure”. Moreover, using these secrets added a whole lot of extra lines in our Jenkinsfiles. And, finally, we also had another DevOps itch to scratch – very little of this was handled as “Infrastructure as Code”[2].
Thus, we decided to allocate a few days of our newly created 2021 team roadmap, to investigate Hashicorp’s Vault[3], for reasons such as:
What can go wrong, right?
…Well, let me just give you a heads up if you decide to go down the same road. The tool’s documentation has not been shown the same level of love as other Hashicorp open-source projects. Some complex terms are not explained, and misconfigurations are common! Moreover, even though they are both Hashicorp’s products, the Terraform provider for Vault is still under development. So, keep these things in mind as you dive deeper into Vault, but keep on reading, if you wish to know how we overcame those obstacles and improved our applications’ secrets’ handling.
On the user side, we decided to allow people to authenticate on Vault using their company email address (a GSuite domain) knowing that strict GSuite group memberships could nicely match to Vault roles. For example, members of the development group should be able to list existing and create new secrets, to use in their code. However, the OIDC[4] backend was not supported by the Terraform provider… But you know the drill, open an issue on Github, while trying to debug the provider in the meantime, and grudgingly moving on to the next item…
Here is how our configuration might look:
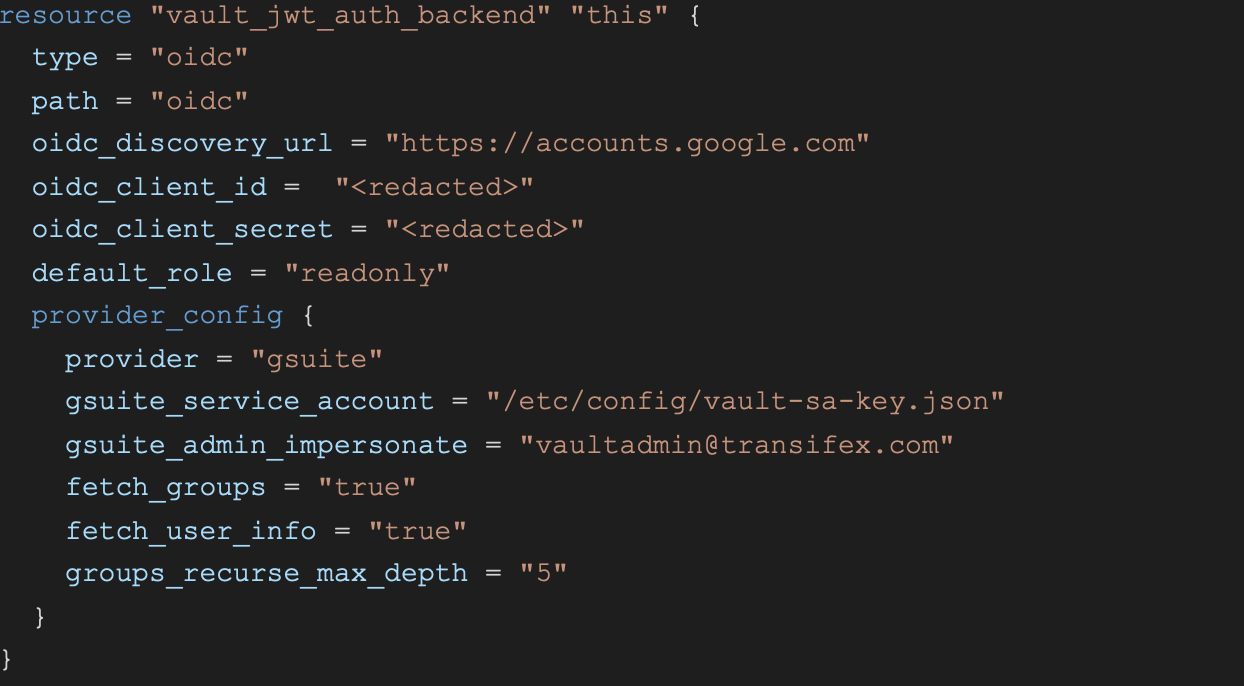
This instructs Vault to create an OIDC backend, which is connected to our GSuite domain. The necessary permissions, service account, OAuth actions on the Google side were done manually, and won’t be mentioned here.
Then, having also created a simple key-value (kv-v2) type engine as our secrets storage, we can create Vault policies and roles, like so:
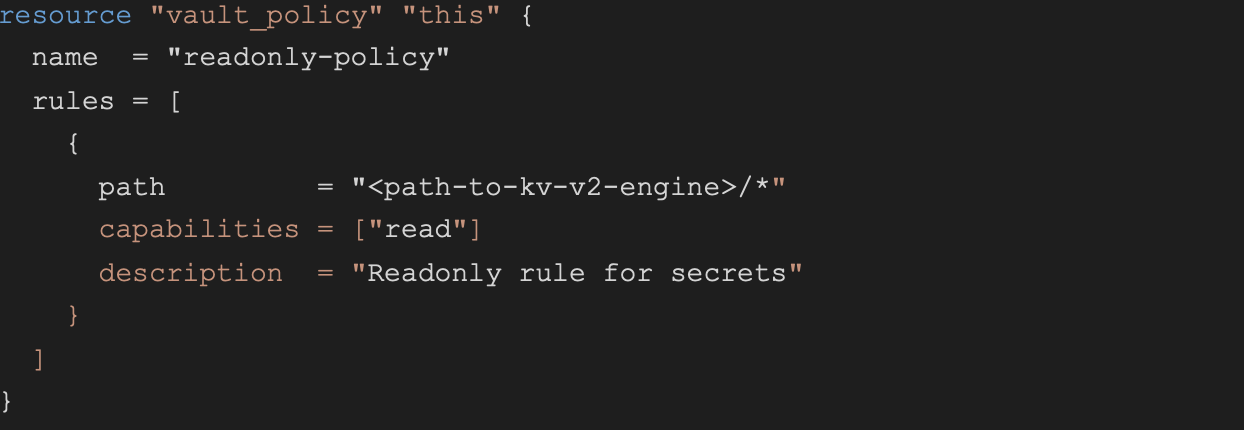
In this simple example, we define a policy named “readonly-policy” which only allows reading secrets (obviously this is not enough for developers who would require extra capabilities like “list”, “create”, “update”, etc).
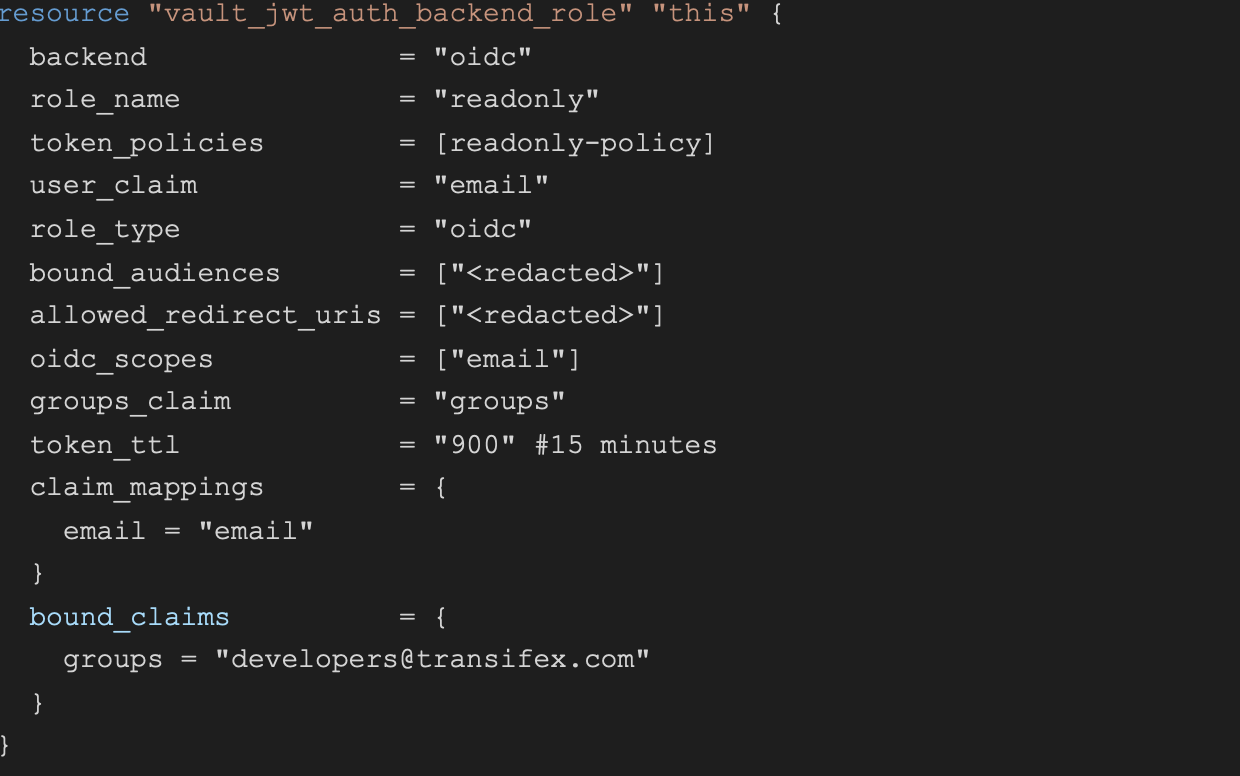
This role, which can be assumed by users in the developers@transifex.com group, is tied to the readonly-policy, and is also the default for everyone trying to log into Vault. The token that is used for the login will expire after 15 minutes, meaning that the user will need to reauthenticate after that time period.
Before moving on, let’s recap. Our secrets have been stored in a simple key-value engine, which allows multiple versions of the secret to be stored (meaning that if the value of the secret is changed, we can restore the previous one). Users can authenticate using their email and assume specific roles that grant them access to specific policies, that in turn grant them access to specific secrets in the kv engine. All nice and neat.
Now, for the juicy part. What about the Kubernetes pods, how can they, and the applications that run inside them, get the secrets they need? For that, we need to enable the Kubernetes Authentication backend, and do some more magic.
First, let’s create a sample policy for appA, allowing it to access the database password of user appA_user:
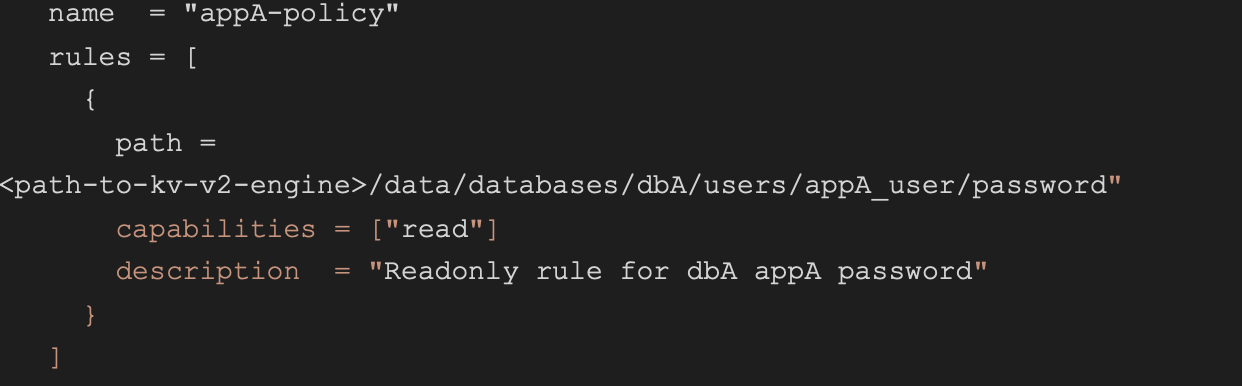
And of course, a corresponding role for appA:

Note that we define which namespaces and which service accounts (that exist in those namespaces) can assume this role. This enables us to be as specific as possible and to avoid granting more permissions than necessary, to more applications than needed.
However, that is not enough. The missing link is the annotations that must exist on every pod, so that Vault knows which secrets to inject in which pod. In the following example, we use some smart helm templating to add the annotations:
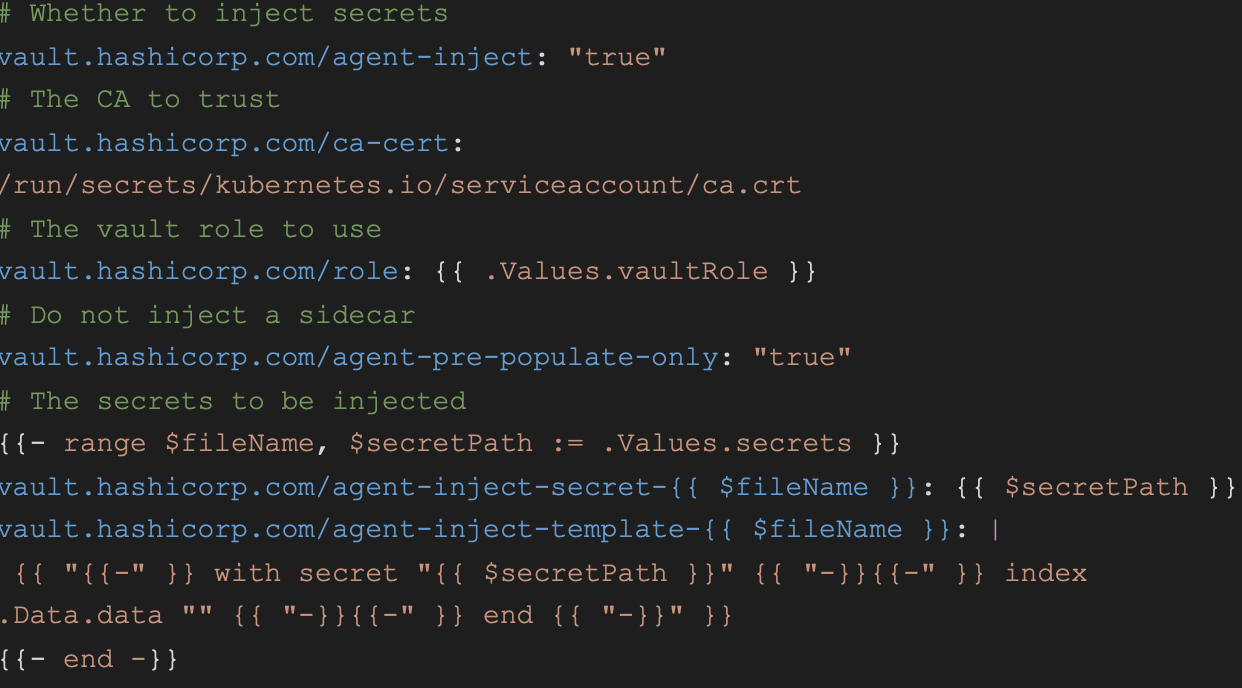
And, thus, in the corresponding values.yaml helm file we would have:

Finally, we can use the “db-password” variable in our code and know that it will get the secret’s value when the pod is initialized.
Having accomplished all that, it is easy to see how this scales for all pods, without hogging many resources (since we added the agent-pre-populate-only flag). Every engineer can safely access Vault and add passwords, tokens and keys that will be required by the application they are developing. Every application can securely grab these secrets from Vault, iff its pod(s) has the appropriate annotations, and the corresponding role is accessing the appropriate policy. Everything is neat and tidy, and in its own little sealed box.
But there are even more benefits that we have gained. We are now able to configure automatic rotation for these secrets, with little tweaking. Furthermore, we can continue adding more types of secrets, since Vault offers a variety of engine types. We also have thorough audit logs for everyone and everything that accesses Vault, and we can thus be alerted if something smelly is going on. Finally, our Vault runs in Highly Available mode, meaning that if one of its instances goes down, another will immediately assume duty.
[1] https://en.wikipedia.org/wiki/Advanced_Encryption_Standard
[2] https://en.wikipedia.org/wiki/Infrastructure_as_code